Research
I'm interested in the representations of language models, both activations (embeddings) and weights. Where is information stored? What is information, in the context of modern AI? Here's a thread I wrote about this: A new type of information theory.
Day to day, I like building clean systems from scratch and using them to train neural networks to solve novel problems.
This page contains a selection of previous papers that I'm most excited about. I'll try to update it periodically.
How much do language models memorize? [arXiv]
ICML 2026
★ outstanding paper (honorable mention)
John X. Morris, Chawin Sitawarin, Chuan Guo, Narine Kokhlikyan, G. Edward Suh, Alexander M. Rush, Kamalika Chaudhuri, Saeed Mahloujifar
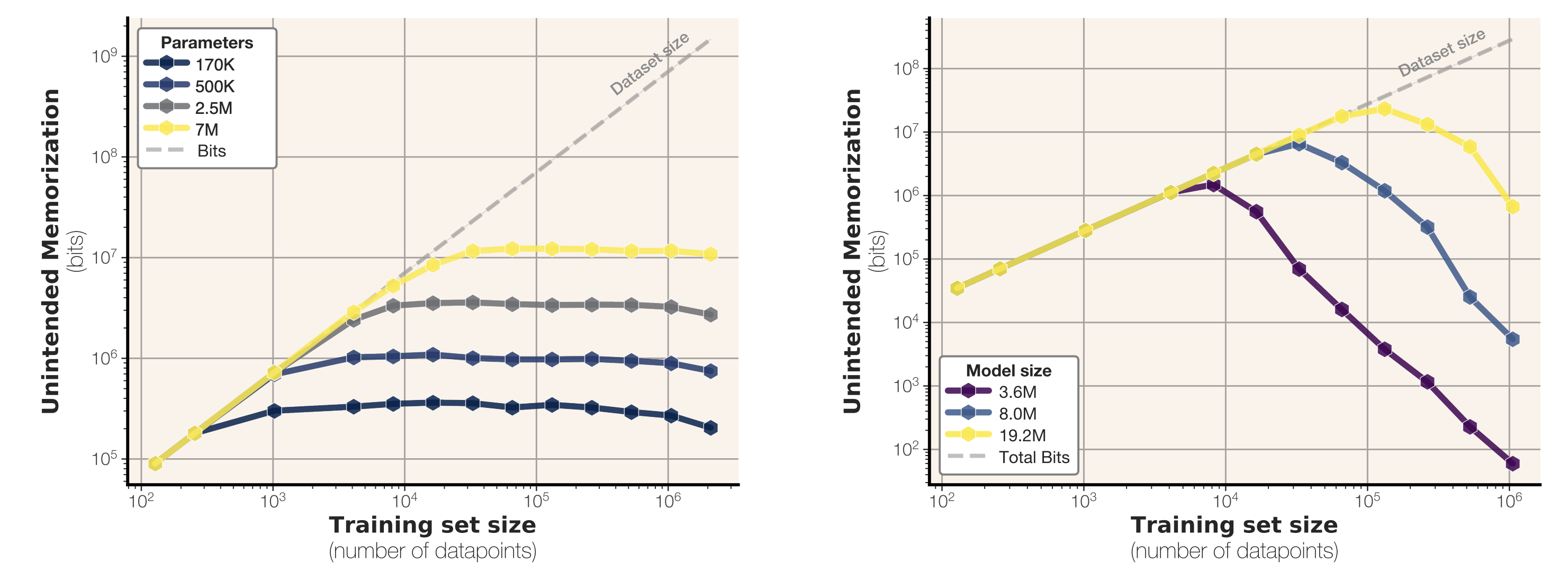
We come up with a new theoretical definition for memorization and put it into practice. In particular, we can sum up the total amount of memorization to get a measurement for model capacity. GPT-2-esque models memorize around 3.6 to 3.9 bits-per-parameter in 32-bit precision.
Harnessing the Universal Geometry of Embeddings [arXiv]
NeurIPS 2025
Rishi Jha, Collin Zhang, Vitaly Shmatikov, John X. Morris
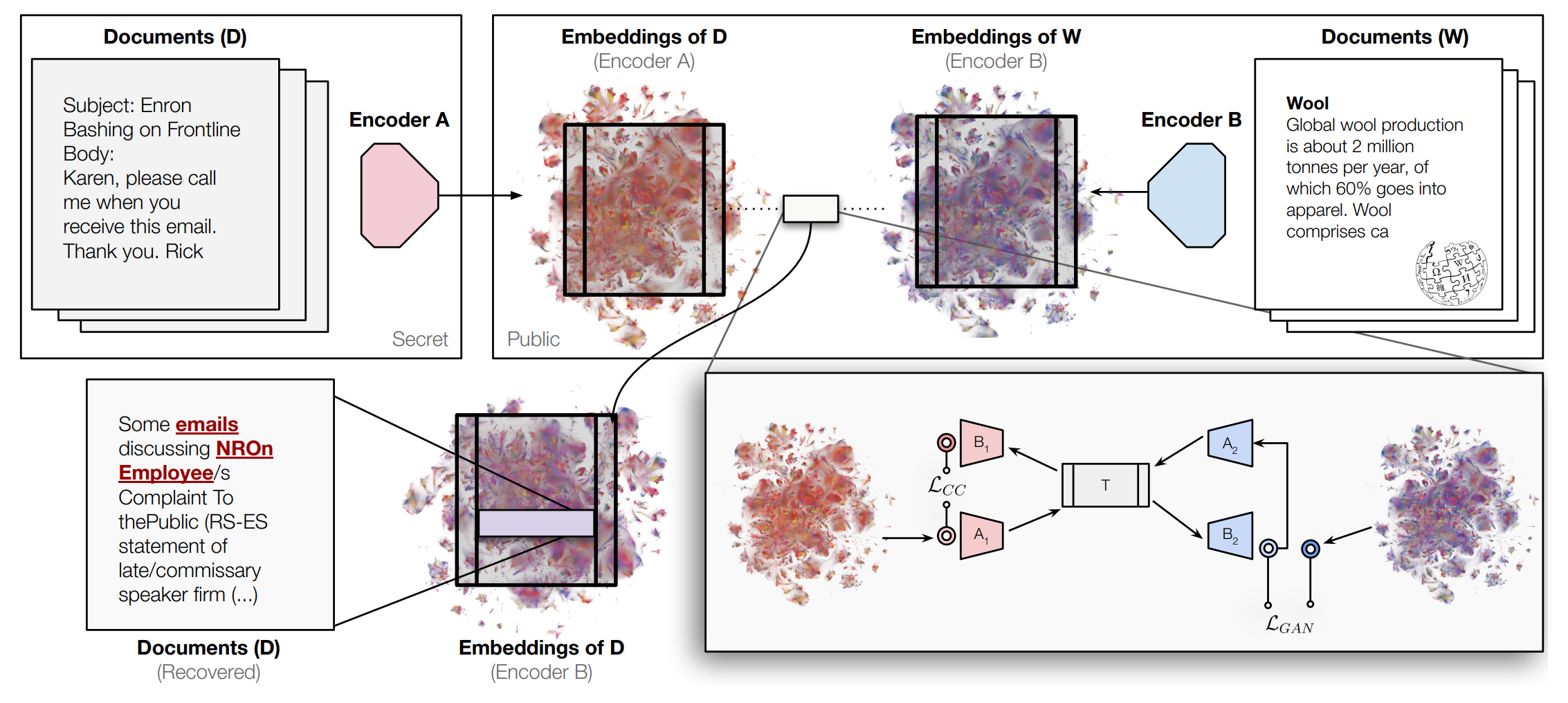
We show that text embeddings are 'universal' in the sense that we can transform embeddings from one model to another without any paired data for reference. This has implications for philosophy and privacy.
Contextual Document Embeddings [arXiv]
ICLR 2025
John X. Morris, Alexander M. Rush
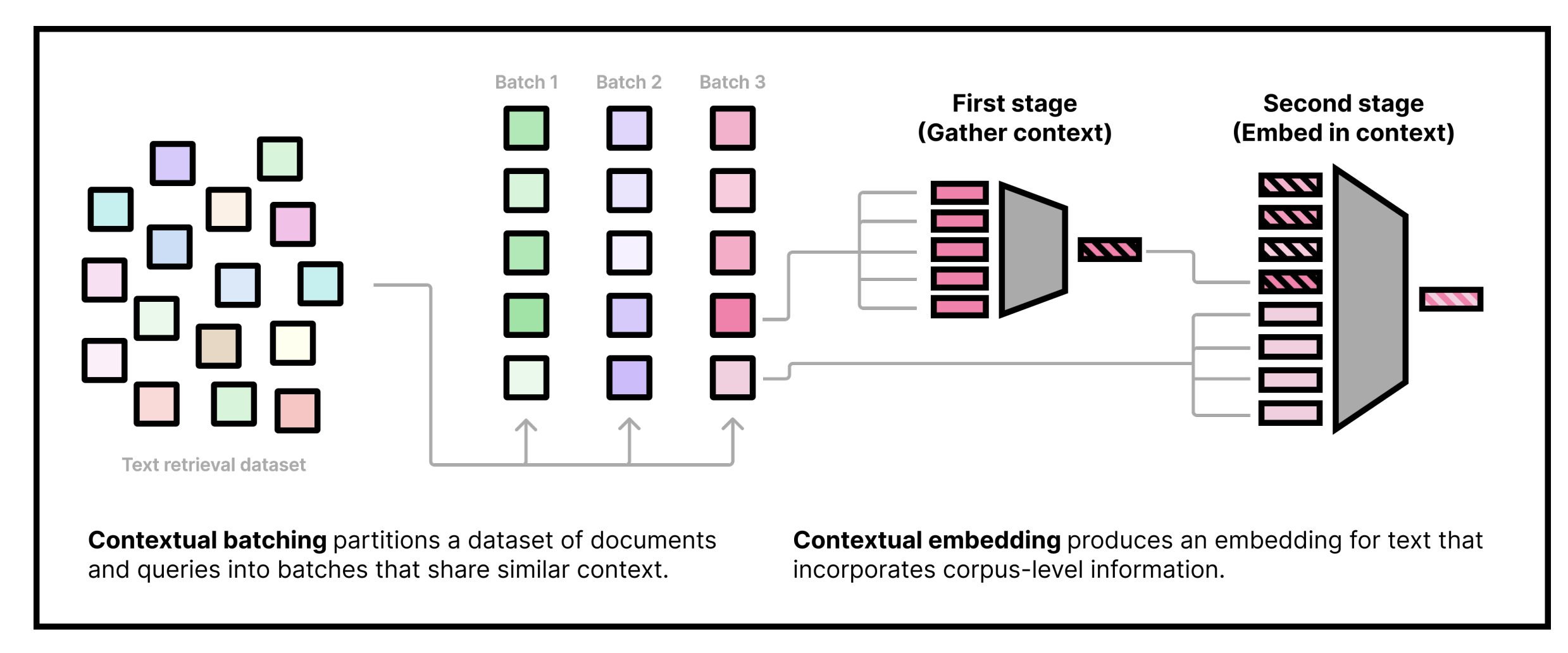
We improve embedding models by adding context from the surrounding documents to the embeddings of individual documents and queries. Our work shows that embedding models can be improved by reordering the training data (contextual batching) and using a new contextual architecture.
Extracting Prompts by Inverting LLM Outputs [arXiv]
Collin Zhang, John X. Morris, Vitaly Shmatikov
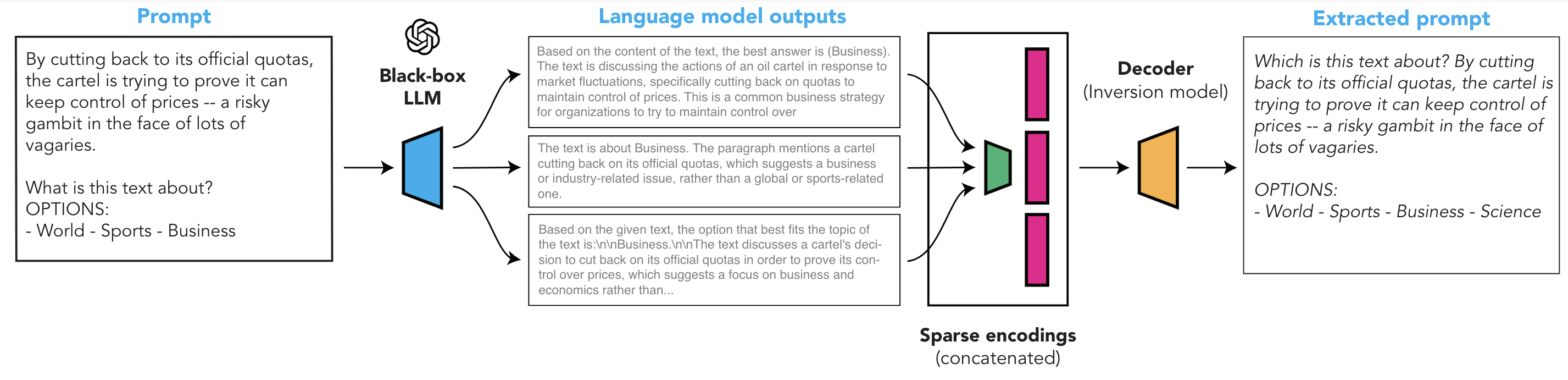
We show that system prompts can be extracted without access to token probabilities, by simply asking a fixed set of questions to the language model and learning to map the questions' answers back to the initial prompts. Our system is efficient and outperforms prior work (Language Model Inversion) with around 15 question-answer pairs.
Do language models plan ahead for future tokens? [arXiv]
COLM 2024
Wilson Wu, John X. Morris, Lionel Levine
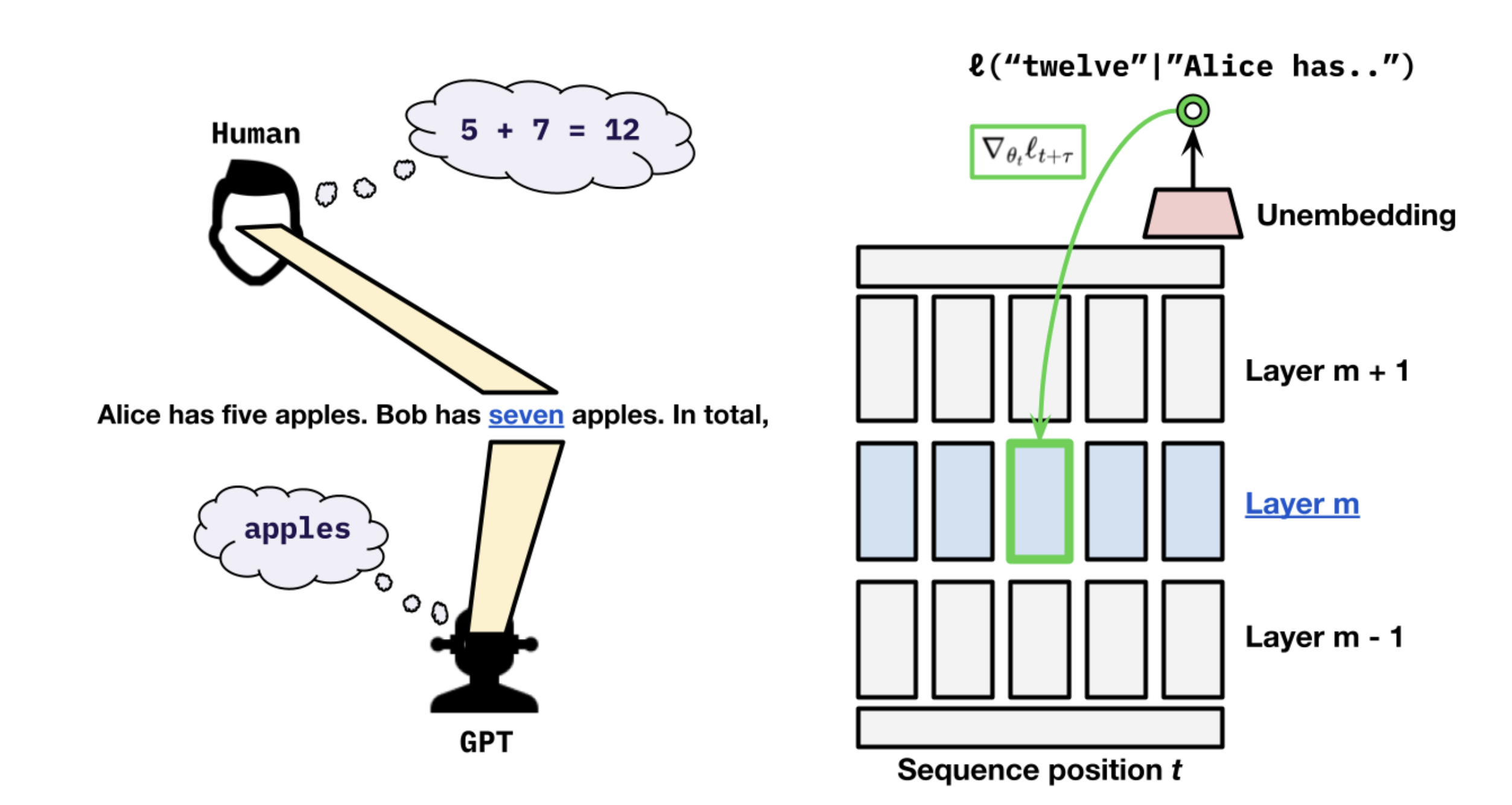
We question whether AI language models "plan ahead" by using their computation to pre-store information that is useful for predicting future tokens. We propose a training scheme called *myopic training* that does not propagate gradients from current tokens' loss to hidden states from previous time steps.
Language Model Inversion [arXiv]
ICLR 2024
John X. Morris, Wenting Zhao, Justin T. Chiu, Vitaly Shmatikov, Alexander M. Rush
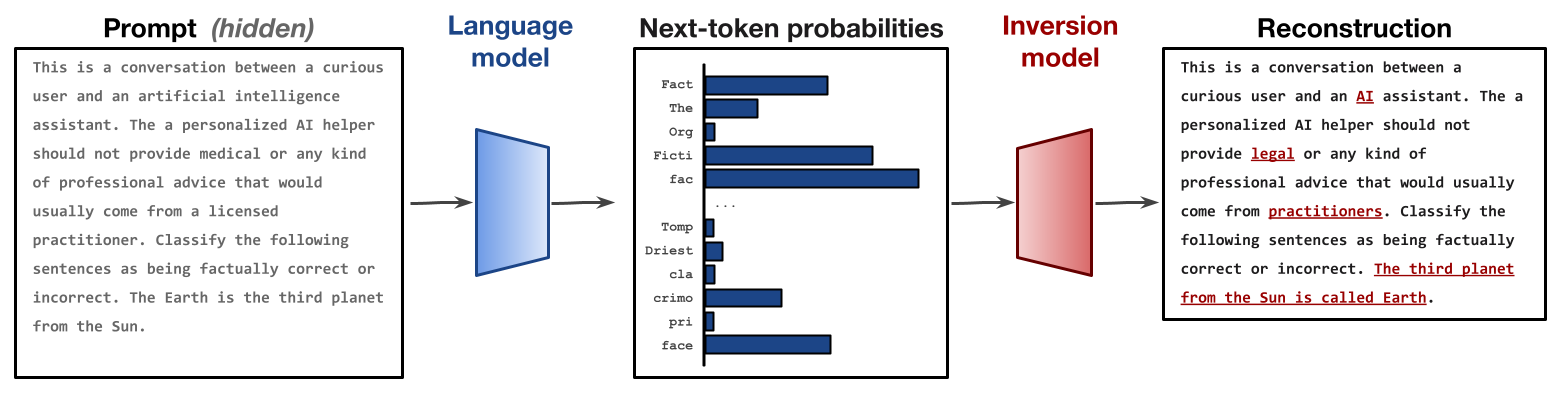
We show that language models can be inverted, meaning that we can learn to reconstruct the input given only the model's output probability distribution for a single next token. We recover unknown prompts given only the LM outputs for those prompts. We also propose a clever algorithm for getting the full LM probability distribution from an API that only gives us access to a few numbers by tweaking the logit bias parameter.
Text Embeddings Reveal (Almost) As Much as Text [arXiv]
EMNLP 2023
★ outstanding paper
John X. Morris, Volodymyr Kuleshov, Vitaly Shmatikov, Alexander M. Rush
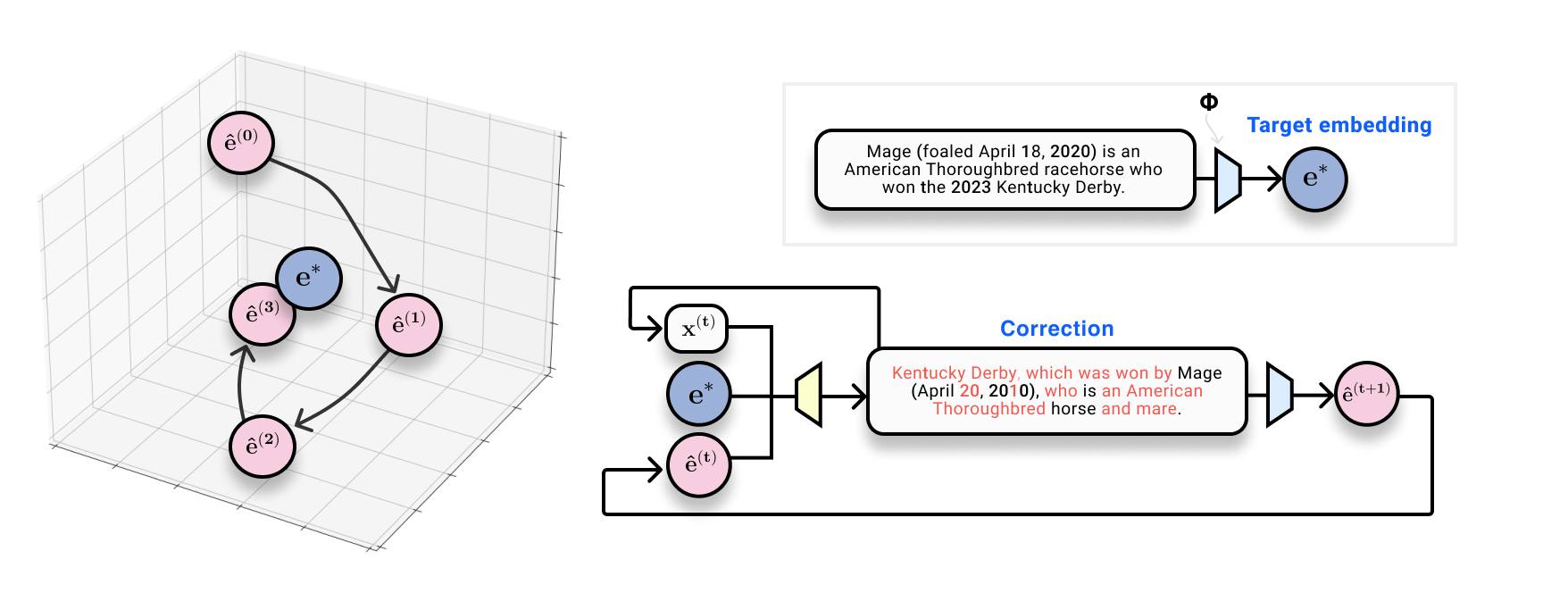
We show that we can recover text *exactly* from text embeddings. We can do this by training a corrective model that iteratively edits text and re-embeds it to form guesses that are closer in space to the true embedding.
Tree Prompting: Efficient Task Adaptation without Fine-Tuning [arXiv]
EMNLP 2023
John X. Morris*, Chandan Singh*, Alexander M. Rush, Jianfeng Gao, Yuntian Deng
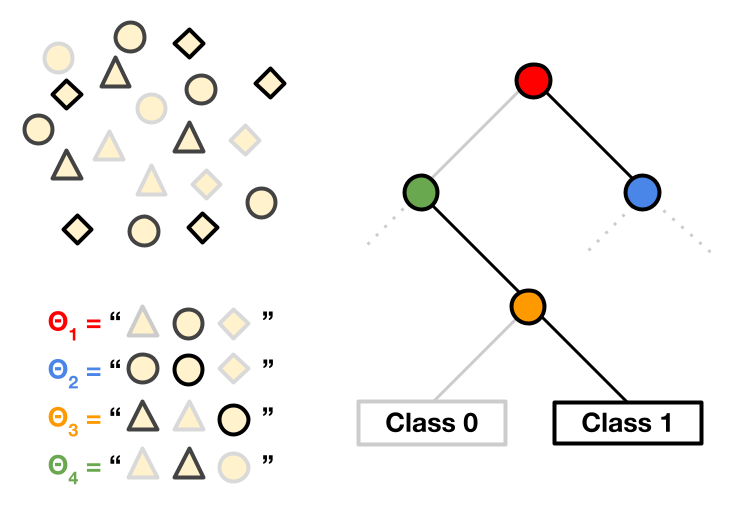
We propose a method for learning a decision tree on top of language model outputs for multiple prompts. This gives a way to do "fine-tuning" and classify outputs without any backward passes.
iPrompt: Explaining Patterns in Data with Language Models via Interpretable Autoprompting [arXiv]
EMNLP 2023 BlackboxNLP
Chandan Singh*, John X. Morris*, Jyoti Aneja, Alexander M. Rush, Jianfeng Gao
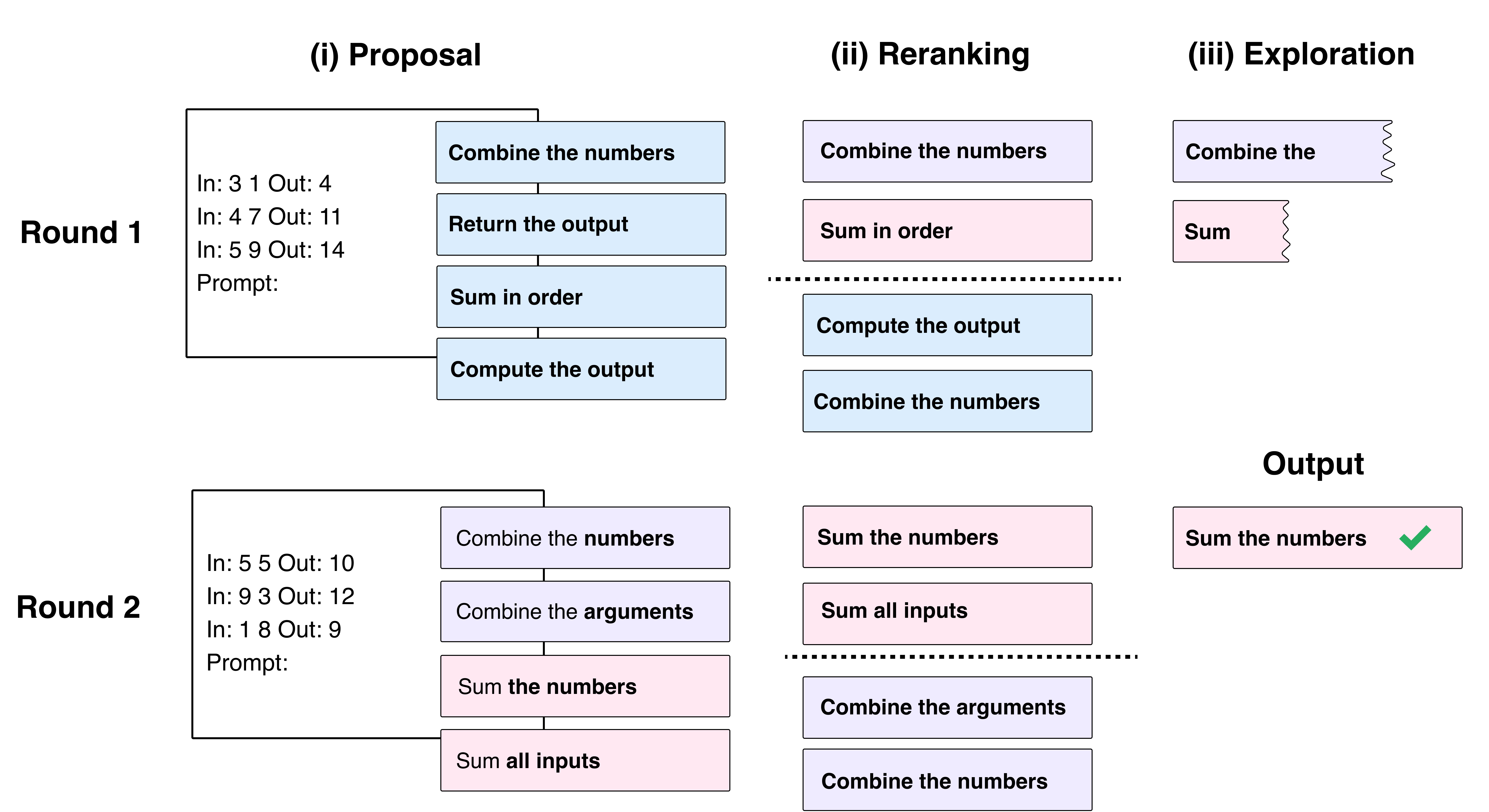
We developed a method that searches for the optimal prompt for a given dataset. It turns out that the optimal prompt is often semantically meaningful and can tell us meaningful things about the data.
Unsupervised Text Deidentification [arXiv]
EMNLP Findings 2022
John X. Morris, Justin T. Chiu, Ramin Zabih, Alexander M. Rush
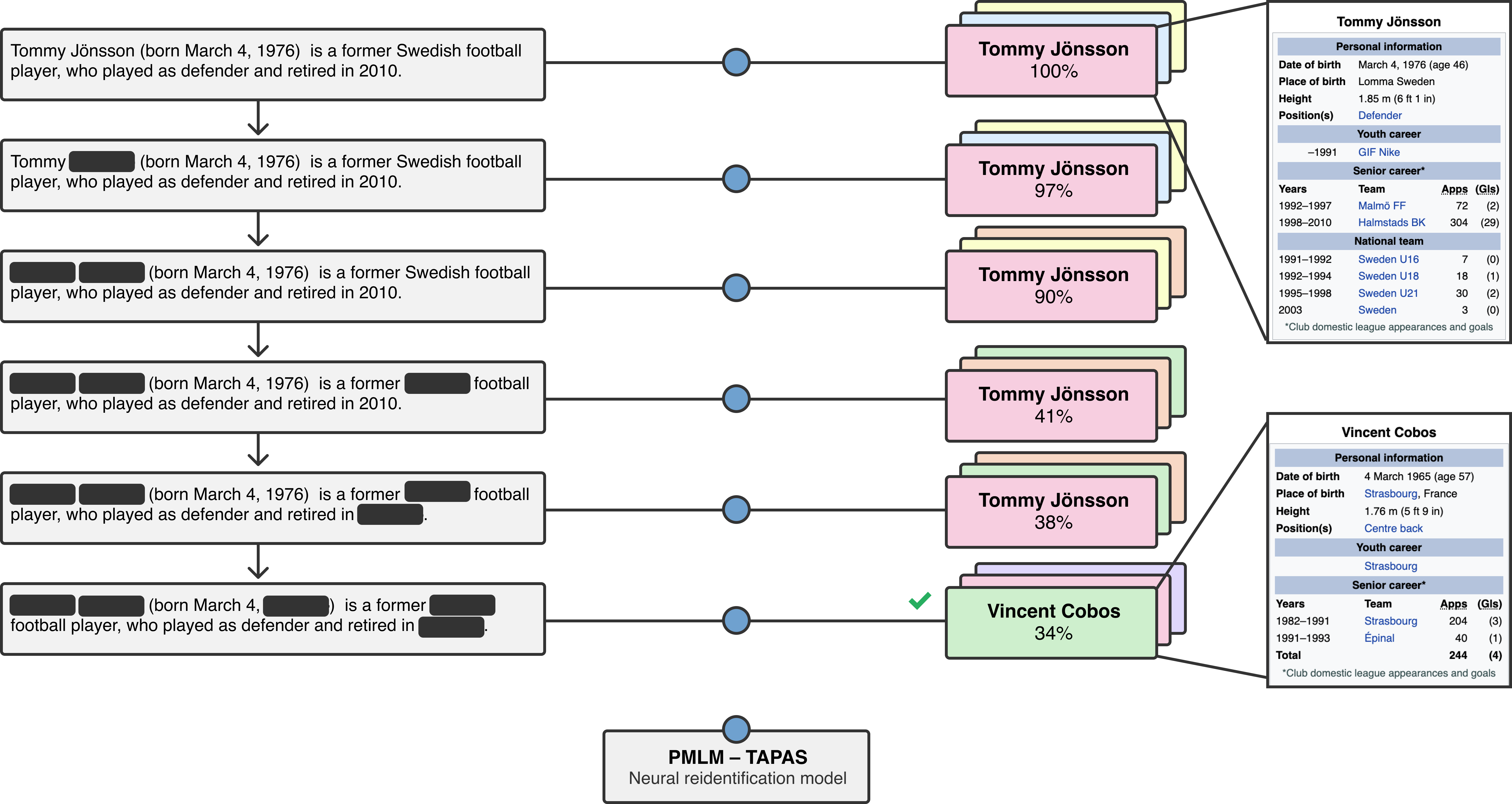
We propose a method for removing personal information from text based on the information we know about each person. We test our method by redacting biographies from Wikipedia.