Contrastive learning is a method for self-supervised learning that’s been popular recently in many areas of machine learning. It’s self-supervised because it allows for the training of models without labeled data. There are lots of different formulas and training techniques that fall under the contrastive learning umbrella, but the basic idea is to learn based on some data points that are similar (“positive pairs”) and some that are dissimilar (“negative pairs”). (For a more mathematical take on contrastive learning, see my previous blog post on InfoNCE.)
Regardless of the exact loss function (InfoNCE, n-pair loss, triplet loss, max-margin loss..), or the domain (vision, NLP, robotics..), almost all contrastive learning papers I’ve seen fall into one of three groups. In this blog post I’ll try and summarize each group and give some examples.
Most contrastive learning papers I’ve seen fall into one of three categories: learn to ignore properties, learn a representation that is unchanging even when one or more functions are applied, learn when things are the same, learn representations that capture similarity between different types of data and thus can be used for nearest-neighbor retrieval, and learn parts of the whole, learn representations that are similar within different views (timesteps, frames, etc.) of the same instance.
Here are three different ways to use contrastive learning:
- learn to ignore properties: to make sure a thing, and an augmented version of that same thing have the same representation – for example, two different crops/colorizations of the same image
- learn when things are the same: to make sure a thing, and a corresponding version of that thing from a different type have the same representation – for example, an image and its caption
- learn parts of the whole: to make sure two different parts of the same thing have the same representation – for example, two different snapshots from the same video
Learn to ignore properties
Given a lot of data points of a single type, one way to use contrastive learning is to learn to produce the same embedding for different versions of the same thing, when that thing is transformed by a given function. This property of embeddings is commonly referred to in the literature as function invariance.
Function invariance is a powerful learning paradigm. Given an unlabeled dataset and a function that should not change the semantic meaning of a given data point we can train a model that produces the same representation for the same thing, even when that thing has been transformed the function.
Another perspective on function invariance is to think of it as data augmentation. If a function is a valid form of data augmentation, then we can use it for contrastive learning: two differently-augmented versions of the same input should have the same representation, and have different representations than the augmented versions of different inputs.
Function invariance across domains
To make this more concrete, let’s look at some examples of function invariance from different areas of machine learning research:
Vision: cropping, resizing, color distortion, color jitter, rotation, partial occlusion (masking), adding noise, blurring, Sobel filtering (SimCLR). Thin-plate spline warps (Unsupervised Learning of Object Landmarks through Conditional Image Generation).
The high-level idea is that an image should have the same “meaning”, and thus the same vector representation, regardless of whether one or more of these transformations was applied.

(These augmentations for images have been used to improve agent performance in lots of recent reinforcement learning work as well, perhaps starting with CURL: Contrastive Unsupervised Representations for Reinforcement Learning.)
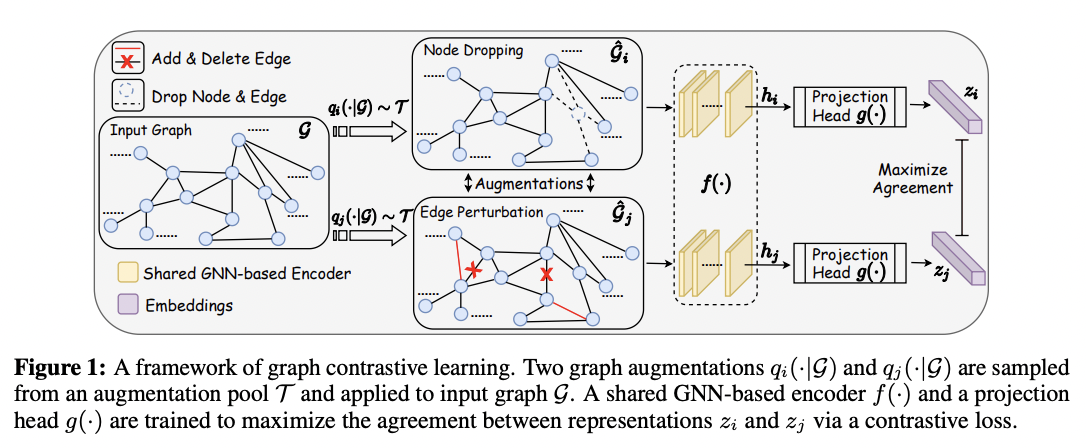
Graphs: Dropping nodes, dropping edges, adding edges, taking subgraphs (Graph Contrastive Learning with Augmentations).
Again, the idea is that these small changes do not change the “semantics” of the graph, and that two graphs differing by these small changes should have equivalent representations.
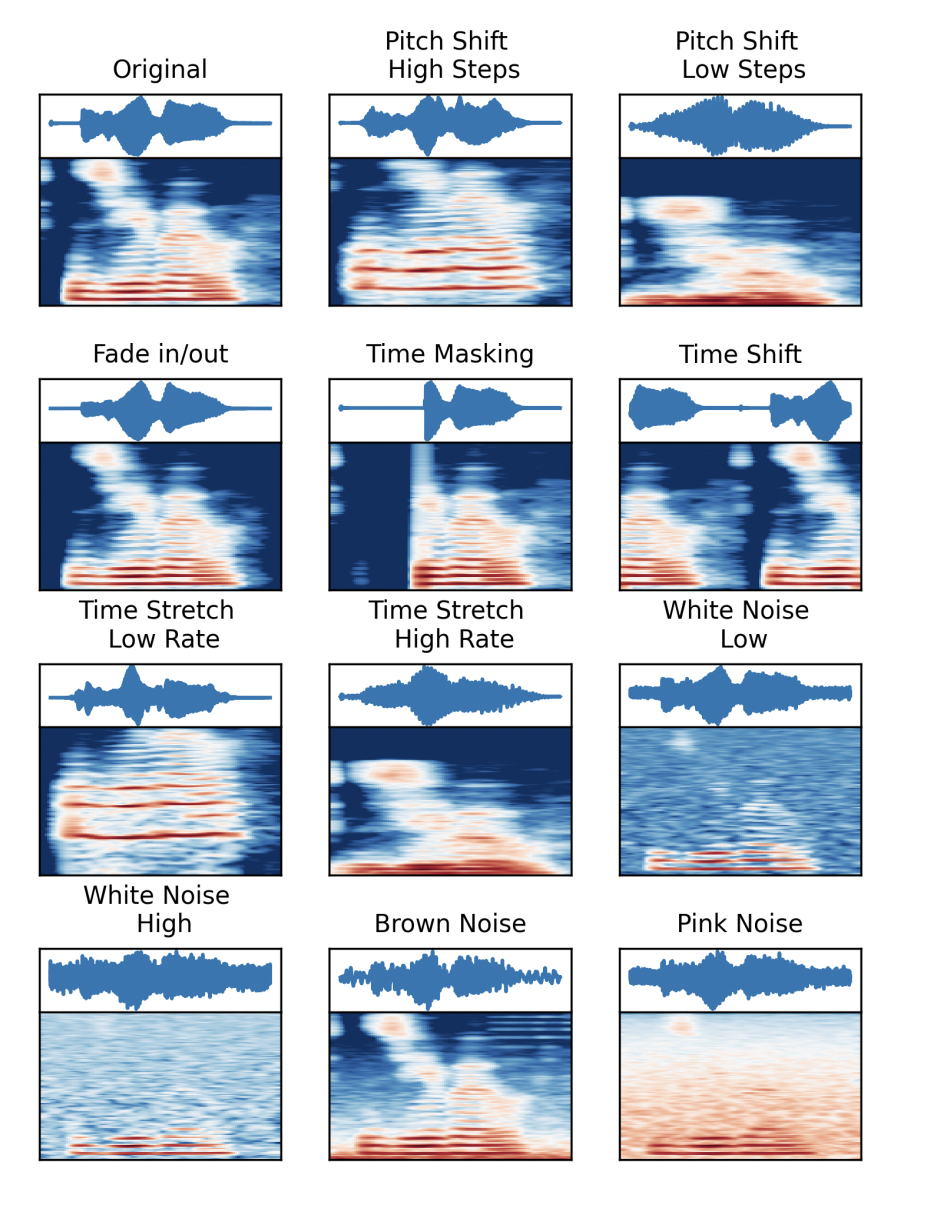
Audio: Pitch shifting, audio fade-in, masking, time shifting, time stretching, adding auditory noise (CLAR: Contrastive Learning of Auditory Representations).
For most tasks, a human listener would consider two versions of the same audio sample with some of these augmentations applied similar, when compared with other audio samples from the same dataset.
Text: word deletion, phrase deletion, phrase order switching, synonym substitution (CLEAR), back-translation (CERT).
Function invariance in the input space
All of the methods depicted to learn from function invariance apply an augmentation to transform the input. An interesting recent development is the enforcement of invariance in the representation space instead of the input space.
If we are able to regularize the same input different ways, then we can produce different representation vectors for the same input, and we can use contrastive learning with the different representations of the same input as positive pairs.
This idea is explored in the 2021 NLP paper SimCSE, which applies dropout in the representation space to augment examples. SimCSE was able to achieve state-of-the-art performance for sentence embedding tasks in a completely unsupervised manner, by applying standard dropout to the same sentence twice, and effectively for the model to learn to reconstruct the input through the embedding.
Learn when things are the same
The second major type of contrastive learning is for retrieval, essentially learning a mapping between types. Given data points of different types, one can use contrastive learning to learn a mapping between the types. This type of contrastive loss can also be seen as an approximation of softmax, where the “neighbors” are used to approximate the full partition function (again see my blog post on InfoNCE).
The use of contrastive learning for retrieval is the driving force behind a lot of work on multimodal models, like CLIP. CLIP uses a contrastive loss to map images to their corresponding captions.
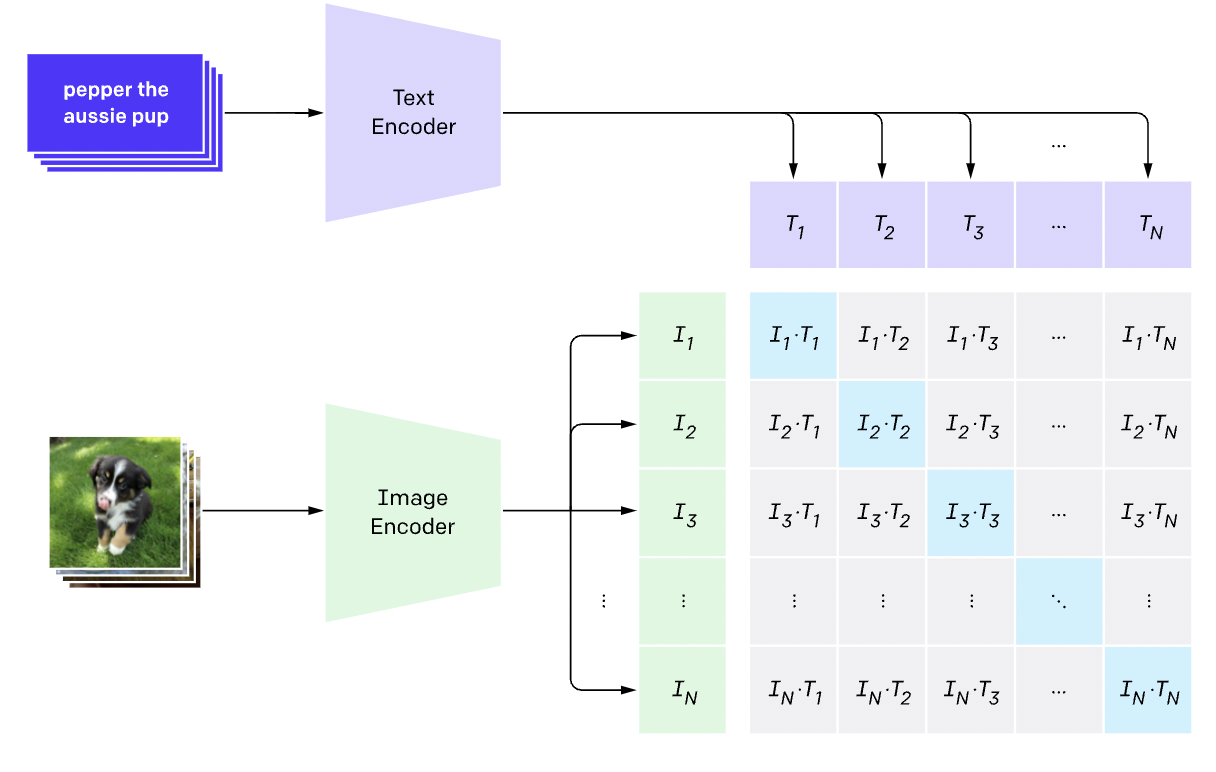
In this manner, contrastive loss can be used to align any dataset of pairs of things. In the previous case, CLIP was trained on a massive dataset of (image, caption) pairs. In setting of text retrieval (like how Google search works), the goal is to retrieve relevant text passages for a given text query. The insight behind the paper Dense Passage Retrieval for Open-Domain Question Answering (or just “DPR”) was to use contrastive learning to learn similar representations between queries and passages. There have been a number of follow-up papers applying contrastive learning to learn to match queries and passages for information retrieval.
The use of contrastive loss to “learn similar representations for similar things” seems especially well-suited for learning multimodal representations. Contrastive learning has also been used for learning alignments between videos and text captions (VideoCLIP), videos and audio (CM-ACC), and speech audio and text (Cross-modal Contrastive Learning for Speech Translation). I expect this trend to continue, and models in the future to be trained on larger datasets with more modalities of data. For example, YouTube is a massive dataset of video frames and audio; with enough compute, one could use contrastive learning to learn representations for videos. (There have been some initial efforts to learn from YouTube with a contrastive loss to match modalities, like this recent work on “Merlot Reserve”.)
Learn parts from the whole
The final use of contrastive learning is to learn similar representations for different parts of the same whole. In the 2018 paper Representation Learning with Contrastive Predictive Coding, a contrastive loss across timesteps is shown to work for unsupervised speech recognition, as well as as an auxiliary loss for reinforcement learning.
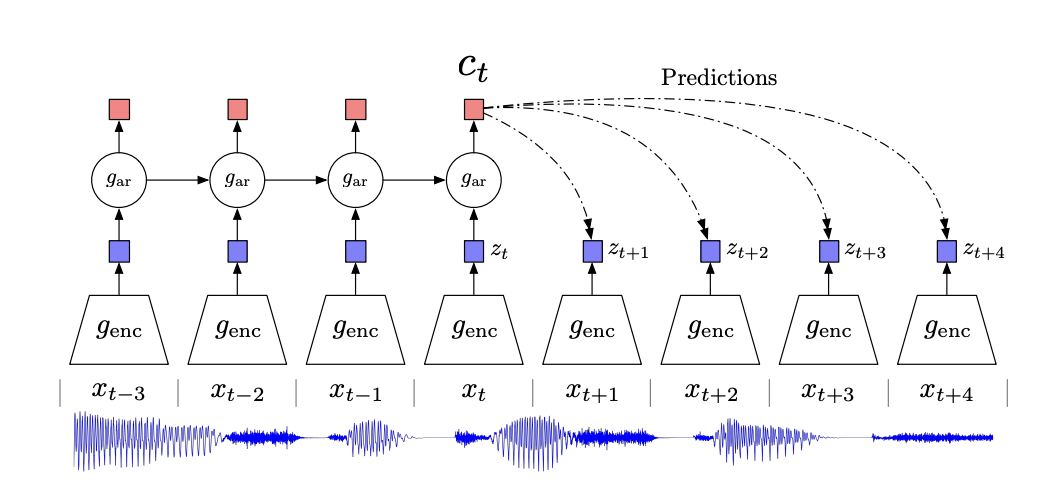
The recent NLP paper Language Modeling via Stochastic Processes applies on the idea of contrastive predictive coding to text generation. Here, the idea is that contextual representation $z_t$ (which will be used to generate text) will be close in representation space to the representations $z_{t-1}$ and $z_{t+1}$.
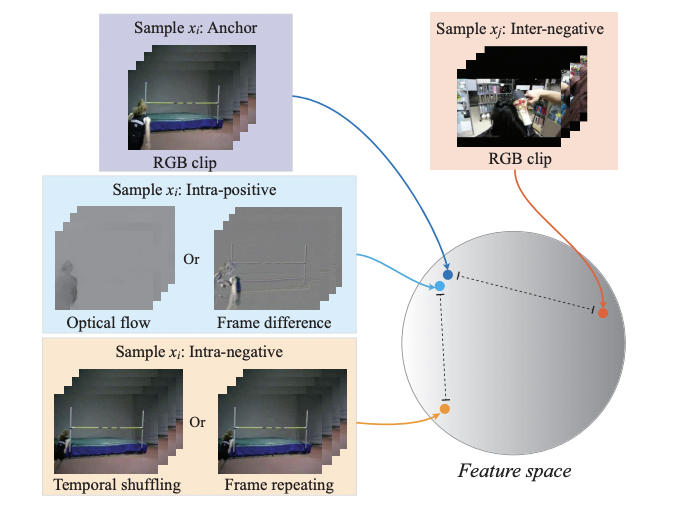
Learning parts from the whole has been also used to learn from video data. Here, the idea is that snapshots from the same video should have similar representations, and snapshots from different videos should have different ones. One early paper on the idea is Self-supervised Video Representation Learning Using Inter-intra Contrastive Framework, although the use of learn-parts-from-the-whole contrastive learning has been explored in lots of different research.
Conclusions and thoughts on future work
This blog post presented my own mental model for contrastive learning, which divides contrastive learning research into three groups. As with any taxonomy (or research in general) the lines are fuzzy and unclear in some places. For example, there is a lot of overlap between learning parts of the whole and learning to ignore properties, since function invariance is typically used to enforce representation similarity between different crops or other sub-parts of a single instance.
And although I did do reading and research before writing this post, the post’s content relied on a roadmap comprised mostly of research papers that I already knew through prior experience, so the content presented is likely biased and incomplete. Please reach out to me if you know of some important work that should be mentioned in the post but wasn’t, or if I mischaracterized some research in any way.
I hope this post has been able to enrich your own understanding of contrastive learning and maybe given you some ideas for future research. Maybe your domain has priors that can be encoded as functions and used for contrastive learning via function invariance. Or perhaps you know of a dataset of pairs of things that could be used for contrastive learning via “learning when things are the same”. Or maybe you can think of a new application for contrastive learning that doesn’t fit in these three categories (if you do, please let me know!)